守护进程
守护进程(daemon)是生存期长的一种进程。它们常常在系统引导装入时启动,在系统关闭时才终止。它们没有控制终端,所以它们一直在后台运行。UNIX系统中有很多守护进程,它们执行日常事务活动。
编写守护进程
- 首先调用
umask设置文件模式创建屏蔽字。如果守护进程要创建文件,那么它可能要设定特定的权限,继承而来的文件模式创建屏蔽字可能会屏蔽某些权限。一般调用为umask(0)。 - 调用
fork保证守护进程不是一个进程的组长进程,同时获得一个新的进程ID。 - 调用
setsid创建一个会话 - 再次调用
fork以保证当前进程不是会话的首进程,以防止日后打开一个终端时获得一个控制终端。 - 更改当前工作目录为根目录。这样可以防止某些文件系统不能被卸载。
- 关闭不需要的文件系统,通知把标准输入、标准输出和标准错误重定向到
/def/null,这样可以防止某些利用这些描述符的库函数不会得不到描述符而出错。
一个将普通进程转换成守护进程的函数:
1 | void daemonize(const char *cmd) { |
syslog
守护进程的一个问题是如何处理出错信息,因为它没有控制终端,所以不能简单的写到标准错误上。可以利用syslog来记录守护进程的错误信息。syslog的组织结构如下:
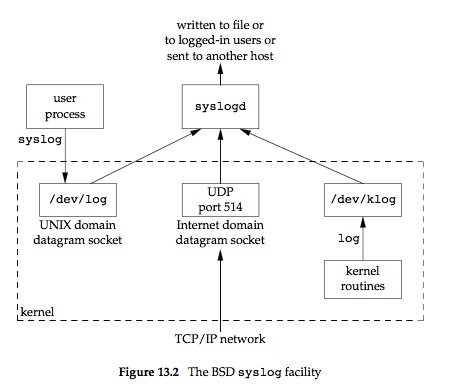
有以下三种产生日志消息的方法:
- 内核例程调用
log函数。 - 大多数用户进程(守护进程)调用
syslog函数产生日志消息 - 无论一个用户进程是否在此主机上,都可将日志消息发向UDP端口514.
syslog的接口为:
1 | #include <syslog.h> |
文件锁和单实例守护进程
fcntl函数可以用来给一整个文件或者是文件的部分区域加建议锁。文件锁分为shared lock和execlusive lock,一个文件可以加多个shared lock,就如同可以有多个读者一样,但是一个文件只能加一个exclusive loc,而且文件要么加shared lock要么加exclusive lock,不能同时加两个锁。
在设置文件锁时,需要传入flock结构的指针。
1 | struct flock { |
需要说明的是,如果l_len被设置成0,那么从l_whence和l_start指定的位置开始到文件的末尾都被加上了文件锁。
fcntl有三种和文件锁有关的操作:
- F_GETLK:
flock参数表示调用者这时候想要加上的锁,如果锁能被加上,那么fcntl并没有实际上锁,它将l_type置为F_UNLCK。如果不能上锁,那么就把文件锁的相关信息填入flock参数中。 - F_SETLK:给文件设置锁,如果另外一个进程已经持有锁而使得当前进程无法获得锁,返回-1。
- F_SETLKW:和F_SETLCK一样,但是当锁无法获得时,调用进程被阻塞,直至锁可用。
需要注意一点是,当对应的文件被关闭时,其上的锁被自动释放,子进程也无法继承父进程的锁。当拥有锁的进程终止时,锁也被自动释放。
flock接口也可以获得文件锁(另外一种文件锁,不一定和上文的文件锁兼容),不同的是,子进程可以继承父进程的文件锁,但是子进程得到的只是文件锁的引用,即如果子进程释放文件锁,那么父进程的文件锁也被释放。具体可以参看flock(2)的manual。
我们利用fcntl函数设置文件锁,只有当前运行的守护进程拥有文件锁,之后尝试启动的守护进程都将无法得到该文件锁,从而无法启动,于是就可以达到单实例守护进程的目的。
1 | #include <syslog.h> |
在运行一次之后,我们尝试在此运行,查看/var/log/syslog得到:
1 | Oct 23 17:00:35 localhost a.out: daemon already running |
使用sigwait以及多线程处理信号
守护进程一般在接受到SIGHUP信号后重新读区其配置文件。这是因为守护进程没有控制终端,它永远不会收到来自终端的SIGHUP信号,那么就可以将SIGHUP信号重复使用,收到该信号就重新读取配置文件。
一个例子:
1 | #include <syslog.h> |
我们将SIGHUP的处理函数恢复的到默认之后(否则进程忽略这个信号,sigwait永远不会见到它),阻塞所有信号,然后创建一个线程处理信号。该线程的唯一工作是等待SIGHUP和SIGTERM。当收到SIGHUP是就重新读取配置文件。